시계열 분석은 보통 시간 순서로 정렬된 데이터를 분석하는 것을 의미합니다. 그래서 보통 주가 등의 financial data나 기온 변화 등에 대한 데이터를 많이 사용합니다. 제가 시계열분석을 공부하고자 마음먹은 이유도 저 financial data를 잘 다루고 싶어서 입니다.
거두절미하고, 제가 오늘 공부한 내용을 바로 소개해드릴게요~
저는 데이터캠프에서 시계열분석에 대해 공부하고 있는데 관련 데이터를 제공해주지 않아 제가 간단한 데이터를 다운받았습니다!
https://trends.google.com/trends/?geo=KR
Google 트렌드
trends.google.com
여긴 구글에서 특정단어를 검색한 횟수를 날짜별로 제공해주는 사이트인데요..! csv파일도 쉽게 다운 받을 수 있고, 시계열에 대해 간단히 알아보기 좋을 것 같아서 가져왔어요!
저는 '다이어트' 와 '운동' 에 대해서 알아봤습니다.
Datetime으로 인덱스 변환하기 (pd.to_datetime())
가장 먼저 시계열데이터를 가공하기 위해선 제공된 index 형태를 datetime으로 바꿔야합니다. 이 때 pandas에서 제공되는 to_datetime()이라는 함수를 쓰면 쉽게 가공할 수 있습니다.
diet.index = pd.to_datetime(diet.index)
exercise.index = pd.to_datetime(exercise.index)위와 같이 하고 print(type(diet.index))을 해보시면 이전에는
<class 'pandas.core.indexes.base.Index'> 형태였던 것이 <class 'pandas.core.indexes.datetimes.DatetimeIndex'>형태로 바뀐 것을 보실 수 있습니다! 차이점이 보이시나요?
만약, 저를 따라하시는 경우, 오류가 뜨실 수도 있는데 그 경우 diet[1:]을 사용해 첫번째 행을 삭제해주시면 됩니다. 첫번째 행에는 문자열이 들어가 있어서 to_datetime에 들어가지 않습니다.
그 다음 확인해보시면 아래와 같은 형태를 띠게 됩니다.

데이터의 plot그려보기 (df1.plot)
그 다음으로는 plot을 그려볼건데요.. 그러기 전에 matplotlib을 미리 import해주셔야합니다.
diet.info()를 확인해보시면 해당열이 object로 되어있기 때문에 plot을 그리기 전에 미리 numeric한 형태로 바꿔줍니다.
diet["search_diet"] = pd.to_numeric(diet["search_diet"])
exercise["search_exercise"] = pd.to_numeric(exercise["search_exercise"])저는 미리 위에서 column의 이름을 바꿔줬습니다. 혹시 바꾸시고 싶으신 분들은 편하게 바꿔주시면 됩니다.
그러고 나면 아래 코드를 이용해 쉽게 plot을 그려줄 수 있습니다.
diet.plot()
plt.show()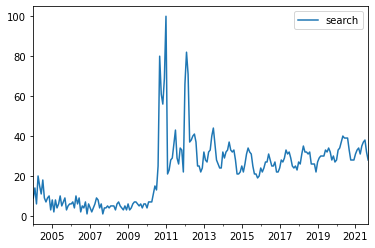
그러면 아래와 같은 결과가 나오신 것을 볼 수 있습니다. 2011년에 다이어트 검색량이 엄청 많아진 것을 확인할 수 있네요.
Slicing
저는 다이어트의 계절 별 추세를 보고 싶기 때문에 짧게 년도 별로 나눠보겠습니다.
diet2020 = diet["2020-01-01" : "2020-12-31"]
diet2018 = diet["2018-01-01" : "2018-12-31"]아래와 같이 데이터를 슬라이싱 해줄 수 있는데, 일년은 보통 1월 1일에 시작해 12월 31일에 끝나기 때문에 저렇게 나누시면 1년치 데이터만 뽑아낼 수 있습니다.
이제 새롭게 slicing된 data의 plot을 봐볼까요?
diet2020.plot()
plt.show()
diet2018.plot()
plt.show()

우측이 2020년, 좌측이 2018년도 비교인데요, 완전히 똑같다고 할 수는 없지만, 새해부터 차근차근 올라가 10월부터 떨어지는 양상이 비슷해보입니다. 조금 더 많은 결과를 비교해봐야하겠지만, 오늘 목적은 slicing과 plot을 배우는 것이기 때문에 그냥 넘어가겠습니다.
시계열 데이터 합치기 (df1.join(df2))
그 다음은 운동과 다이어트의 데이터를 하나로 합쳐서 새 데이터 프레임을 만드는 것을 해보겠습니다.
diet_and_exercise = diet.join(exercise)
그러면 위와 같이 두개의 데이터 프레임이 합쳐진 새로운 데이터 프래임을 확인할 수 있습니다. 한 번 2018년의 두 데이터를 같이 그래프에 그려볼까요?
diet_and_exercise_2018 = diet_and_exercise["2018-01-01" : "2018-12-31"]
diet_and_exercise_2018.plot()
plt.show()
위의 데이터를 통해 두 데이터를 그려보았는데 저는 두 데이터가 비슷하게 움직이는 것 같아 보이긴한네요..
이를 확인하기 위해 상관계수를 확인해볼까요?
상관계수 구하기와 산점도 그리기(df1["column1"].corr(df2["column2"] / plot.scatter(df1["column1"],df2["column2"])
저 그래프의 상관관계를 확인하기 전에 먼저 전체 데이터들의 상관관계를 확인해보겠습니다.
상관관계는 corr 이라는 함수를 이용해 쉽게 구할 수 있습니다
cor = diet_and_exercise["search_diet"].corr(diet_and_exercise["search_exercise"])
print(cor)결과는 0.5082265199265419 으로 강한 상관관계를 가지고 있지는 않다고 나왔네요!
상관계수를 눈으로 보는 방법도 있습니다. Scatter을 이용하는 방법인데요!
plt.scatter(diet_and_exercise["search_diet"],diet_and_exercise["search_exercise"])
plt.show()이 코드를 실행시키면 아래와 같은 산점도를 얻으실 수 있습니다.

눈으로 보기에도 강한 상관관계가 보여지지는 않네요..
방금 배운 코드를 바탕으로 위에서 제가 그린 2018년도의 운동과 다이어트 사이의 상관계수도 쉽게 구할 수 있습니다.
cor1= diet_and_exercise_2018["search_diet"].corr(diet_and_exercise_2018["search_exercise"])
print(cor1)결과는 0.6510923284549441 이 나왔네요.. 전체 상관계수보다는 약간 높아진 것을 확인할 수 있습니다.
상관관계를 구할 때, 알아야할 다른 점은 퍼센트의 변화량을 구해 그 변화량으로 상관계수를 구하는 것인데요!
만약, 다이어트 검색량이 증가하는 추세에 대해 운동 검색량이 증가하는 추세를 볼 때 사용할 수 있습니다.
이 때 변화량역시 함수 하나로 손 쉽게 나타낼 수 있습니다.
pct_change()라는 함수를 이용하면 바로 앞 열과 해당열간의 퍼센트 차이를 반환해줍니다.
diet_and_exercise_changes = diet_and_exercise.pct_change()
diet_and_exercise_changes그리고 방금 만든 가공된 데이터 프레임을 불러보면, 아래와 같은 모습의 데이터 프레임이 반환됩니다.
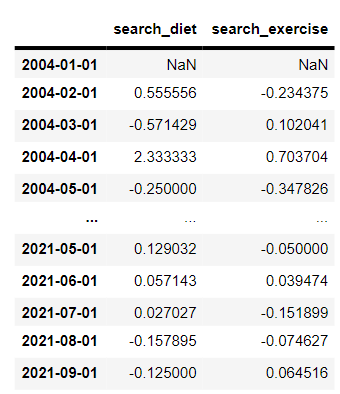
첫 행은 기준이 되는 전 행이 없기 때문에 null값으로 반환되는 것을 보실 수 있고, 다른 열은 전 행과의 차이를 알 수 있도록 데이터 프레임이 바뀌었네요..
변환된 데이터 프레임을 바탕으로 산점도와 상관계수를 구해볼게요!
plt.scatter(diet_and_exercise_changes["search_diet"],diet_and_exercise_changes["search_exercise"])
plt.show()
눈으로만 봐도 확연히 아까보다는 줄어든 모습을 볼 수 있는데요! 제가 데이터를 열심히 골라온 것이 아니라, 오늘 배우는 함수를 배워보는 용도로 가볍게 들고온 것이기 때문에 좋은 결과는 얻지 못한 것 같네요!!
cor2 = diet_and_exercise_changes["search_diet"].corr(diet_and_exercise_changes["search_exercise"])
print(cor2)역시, 상관계수는 0.15517060099772007로 매우 낮게 나왔습니다!
오늘 배운 내용은 인덱스를 데이트 타임 형태로 변환하는 법, 시계열 데이터를 슬라이싱하는 법, 두 개의 시계열 데이터를 합치는 법, 산점도를 그리고 상관계수를 구하는 법이었습니다!
※ 제가 블로그를 시작한 이유는 타인에게 정보를 전달하기 위한 목적보다는 제가 공부하는 내용을 기록하려는 목적이 더 크기 때문에 혹시 보시다가 틀린 부분이 있으면 편하게 알려주셨으면 좋겠습니다 :)
※ 또한 실력이 아직 좋은 편은 아니기에 혹시 누군가가 제 블로그를 보신다면 같이 공부해가는 느낌으로 보셨으면 좋겠습니다.
※ Datacamp에서 제공되는 시계열분석 강의를 기반으로 공부하고 있습니다.
'시계열분석' 카테고리의 다른 글
| prophet (0) | 2021.11.14 |
|---|---|
| ARIMA&SARIMA (0) | 2021.11.07 |
| Fitting the ARMA model (0) | 2021.10.10 |
| 시계열분석 _ ARMA모델 개념정리 (0) | 2021.10.03 |
| 시계열분석 _ 자기상관과 ACF (0) | 2021.09.25 |



